


量子位 | 公众号 QbitAI
人类一眼就能看懂的文字,AI居然全军覆没。
来自A*STAR、NUS、NTU、清华、南开等机构的研究团队,最近有个新发现:
不管是OpenAI的GPT-5、GPT-4o,还是谷歌Gemini、Anthropic Claude,甚至国内的Qwen、LLaVA,在面对一些“看得见但读不懂”的文字时,全都表现极差,直接“翻车”。

先切再叠,AI束手无策
VYU团队设计了两个小实验:
1、选取了100条四字成语,把每个汉字横切、竖切、斜切,再把碎片重新拼接。

人类读起来毫无压力,AI却几乎全错。

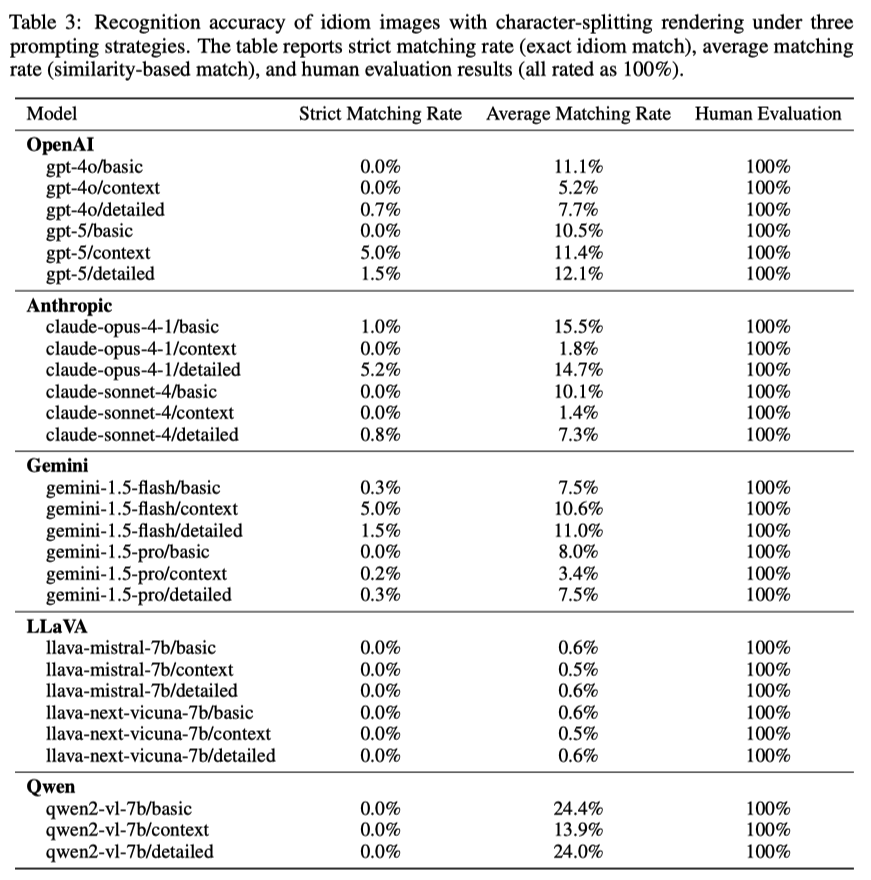
2、挑选了100个八字母英文单词,把前后两半分别用红色和绿色渲染,再叠加在一起。
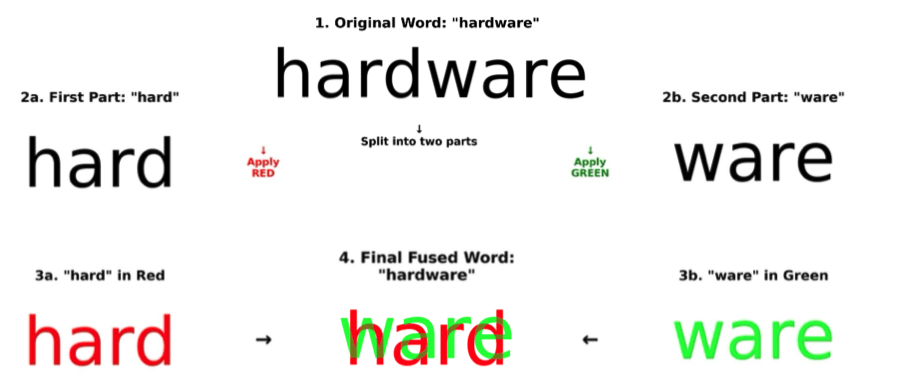
对人类来说,这几乎不构成挑战——因为我们的视觉系统对红/绿通道异常敏感,大脑能自动分离颜色,然后拼出完整的单词。
但对AI模型来说,结果却完全不同:

即使是最新发布的大模型,在这些问题上也屡屡碰壁。
无论是Gemini 2.5 Pro:


还是Kimi 2(Switch to 1.5 for visual understanding) :


(PS:Kimi 2最终推测的答案是hardline)
又或者Qwen3-Max-Preview:


全都得不到正确的结果。
AI不懂符号分割与组合
对该现象进行分析,VYU团队认为,根本原因在于AI靠模式匹配,不懂文字结构。
人类之所以能“读懂”,是因为我们依赖结构先验——知道汉字由偏旁部首组成,知道英文是按字母组合的。
于是,只要文字稍作扰动(但人类依旧能看懂),AI就会彻底崩溃。

这个问题之所以值得研究,是因为它关系到AI落地的核心挑战:
-
在历史文献与科学笔记整理中,AI无法像人类一样从残缺文字中恢复含义。
-
在安全场景里,攻击者甚至可以利用这种“盲点”绕过AI审查。
在历史文献与科学笔记整理中,AI无法像人类一样从残缺文字中恢复含义。
在安全场景里,攻击者甚至可以利用这种“盲点”绕过AI审查。
VYU团队认为,要想让AI拥有类似人类的韧性,必须重新思考VLMs如何整合视觉与文本——
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏





